I will be the one to say it. AI disappointed most of us in 2024. We started the year with Chatbots that were good enough to be entertaining but not good enough to replace a human when accuracy or creativity were important and we ended the year with… well, the same thing. The conversations are a little more entertaining, but the world has not been changed.
In 2023 and 2024 we were so enthralled by the first couple leaps of Generative AI that it seemed likely that getting rid of hallucinations, creating reasoning through the use of agents and multi-step thinking (like OpenAI o1) would very soon propel us to another giant leap. Instead, the growth has been much more incremental.
I still believe that AI is going to change the world. This is a common problem in technology. I’m very much reminded of Bill Gates’ quote, “Most people overestimate what they can do in one year and underestimate what they can do in ten years.” This is where the first part of my key to AI Investment comes in, patience.
Patience will be required in two ways.
First, there’s the obvious, don’t give up on AI. The underlying technologies are expanding at an unbelievable rate; AI’s ability to reason jumped forward in 2024 (I posted about OpenAI o1), Agentic AI showed potential, an AI effectively won the nobel prize for Chemistry, and the legal frameworks for AI are starting to come together. There may be more work required to make AI practical than we thought, but that work is being done.
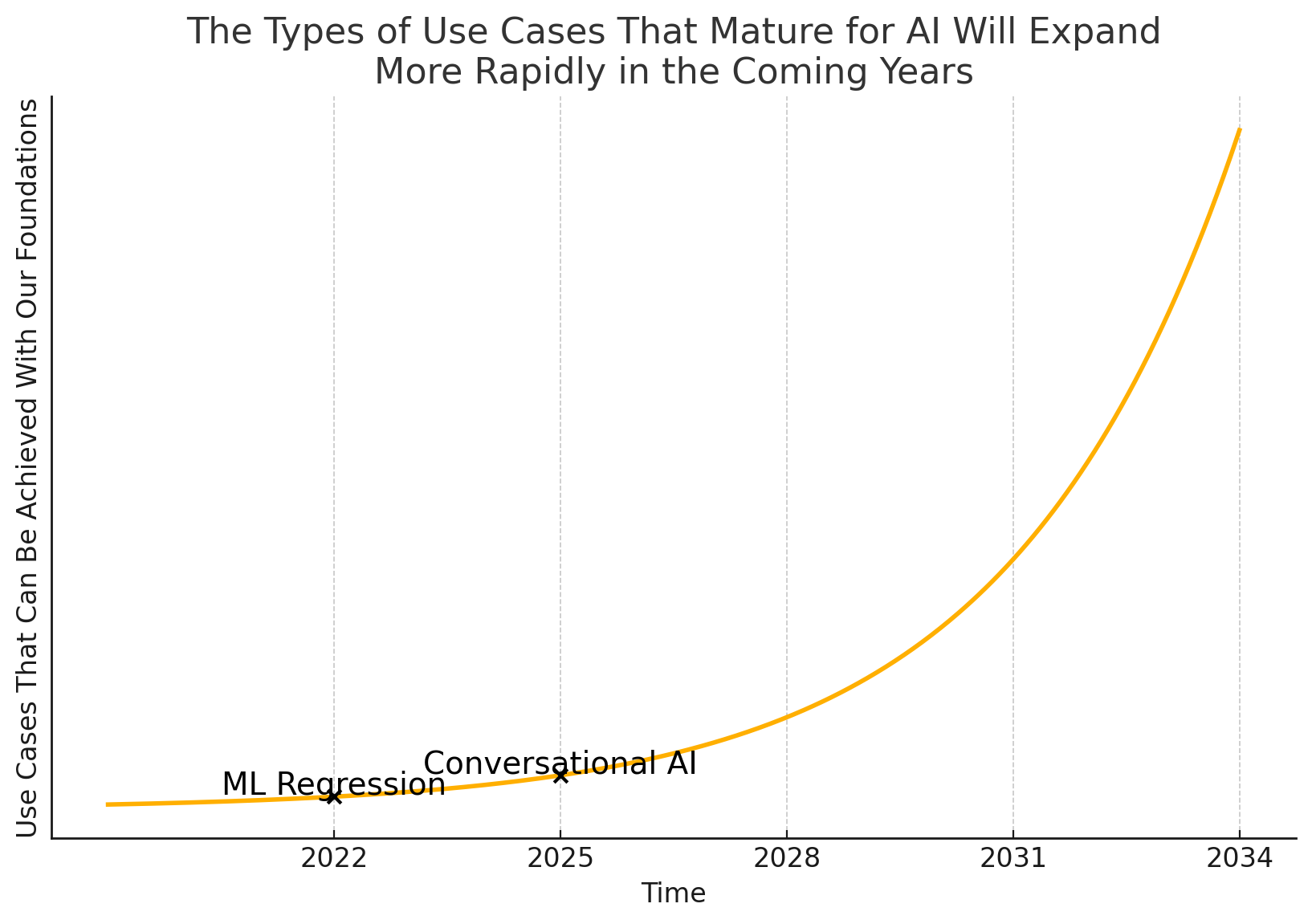
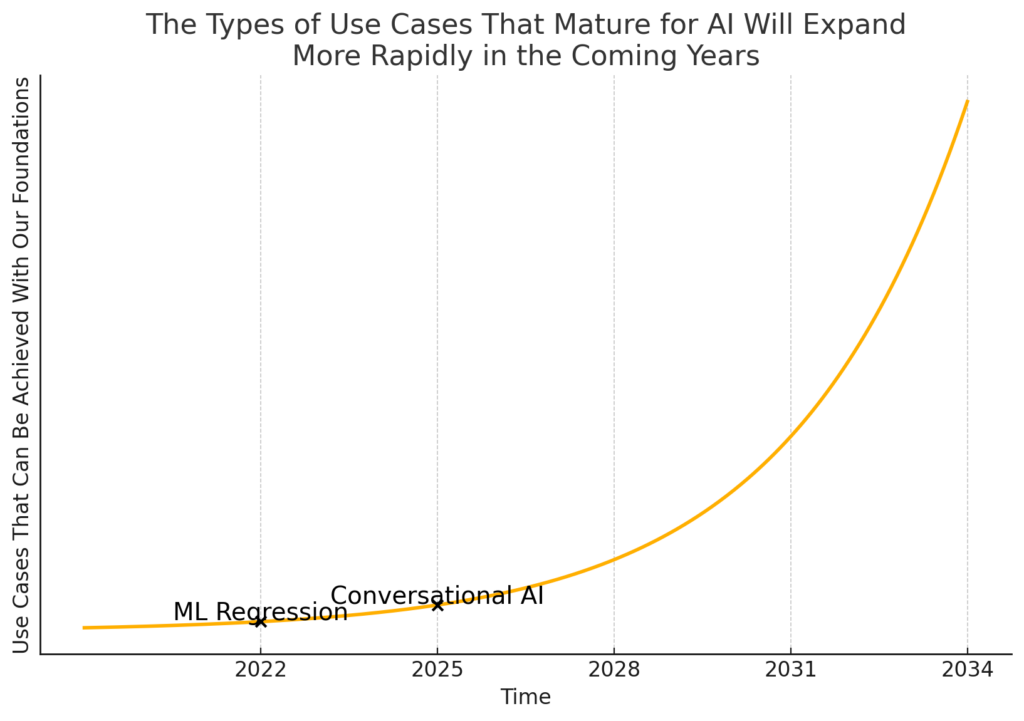
The second way that patience is required is a little bit less obvious. You need to exercise patience in not throwing good money after bad on Use Cases that are impossible today. One thing that has become clear about AI is that it takes an ecosystem to achieve a use case. Unless you’re NVIDIA or Google you’re not creating your own LLMs, building your own GPUs, writing your own vector algorithms, etc… You have to use what you can buy. I consider all of these things to be your “AI Foundations”… no matter how hard you try as a company, some use cases are just not possible with the current set of AI Foundations.
Think of it using this chart:
There are some use cases that are just above the yellow line and not practical to consider today. This is particularly true for use cases for which there isn’t “partial” value. Think about one of the most talked about use cases… replacing your software developers with AI Agents. It’s just not feasible yet with the foundations that we have. The LLMs are not creative enough, the understanding of requirements is not deep enough, the reasoning is not up to the level of critical thinking. Additionally, this problem doesn’t have interim value milestones as currently framed. Either the AI can perform as a software developer or it can’t. It doesn’t make my application better if it submits code that is only 40% right and fails all the tests.
Patience is necessary to avoid the mistake I’ve seen companies make; they pour more and more resources into these impossible use cases because they see the AI agent go from 40% right to 43% right. They make these incremental gains with painstaking analysis of prompts and patches like adversarial AI. It will never make be close enough to 100% to be used without a fundamental shift in the AI Foundations that we’re building on. Unfortunately, when that shift happens all the work you did on this set of foundations may or may not be applicable. For example, a lot of the prompts written to make ChatGPT 4 try to reason don’t make any sense when they’re fed to ChatGPT o1… so people are just throwing them away.
I know what most of you are thinking… my two recommendations seem to contradict each other. On one hand, I’m saying that AI will be important and you need to continue to invest in it. On the other hand, I’m saying that you should stop investing in many of the AI use cases you think would be most valuable because they’re infeasible. The trick to deploying your 2025 AI investments will be in “The Key to AI Investment in 2025 Part II: Preparation”
In this post, we’re going to try to give Jonabot a little bit of my history so it can answer questions about my past.The concept we are using for the biographical information is Retrieval Augmented Generation (RAG). Essentially, we will augment the AI by giving it access to reference information that’s valuable just before it answers. The best way to think of RAG is as a “cheat sheet”. Imagine asking someone, “Who was the fourth President of the United States?” You would expect them to answer in their own voice, but either with the right answer if they knew it, and if they didn’t, they might guess or say they didn’t know. One of the problems with Generative AI is that it tends to guess and not explain that it’s guessing. This is called a hallucination, and there are several good examples of it. With RAG, we not only ask, “Who was the Fourth President?” but we also give the AI Large Language Model (LLM) the answer (or a document with the answer). This results in an answer that’s in the “voice” of the LLM but contains the right answer. No hallucinations.
The way this is accomplished is to take all of the available information that you want to be on the “cheat sheet” and creating a vector database out of it. This allows that information to be easily searched. Then, when the AI is asked a question, we do a quick search and augment the prompt with the results of the search before putting it to the LLM.
I have seen many clients do things like ingesting their entire FAQ and “help” sections and making them the cheat sheet for their AI Chatbot. This is also useful if you need the Chatbot to be knowledgeable about things that have happened recently (since most LLMs were trained on the internet 2+ years ago). For Jonabot, we want to provide information about me and my history that it wouldn’t have learned by ingesting the internet (since I’m not famous, my wikipedia page the base AWS Titan LLM knows very little about me).
To enable this technically, I created a text document with a whole bunch of biographical information about Jonabot separated into lines. I also broke my entire resume into individual lines and fed them one at a time. I’m not choosing to put this document in my Git repo since, while none of it is private information, I don’t think it’s a good idea to just put all of it out on the internet in one place. Here’s a quick example, though:
And, an example from where I was typing in my resume:
I then created a simple Jupyter Notebook (Biographical_info_import) that works with that file. The notebook does two things:
It creates the Vector Database. It does this by ingesting each line in the document and then committing them to a vector database. For simplicity in this project, I am leveraging the Vector Database that comes with AWS Bedrock, “Titan Embeddings,” and the LangChain libraries to do the establishing and committing. I am also using it locally. This obviously wouldn’t scale for massive usage since it recreates the vector database from the text file every time it runs.
I created a simple query to test how accurately it retrieves information. Eventually, we will use the query results to augment the prompt to the LLM, but for the moment, I want to demonstrate how it works separately.
The results were pretty impressive. I was able to query “raised” and got “Pittsburgh, PA” or “Musical Instruments” and got “Piano and Guitar”. This is, of course, just based on a pure semantic search. The next step is to link these embeddings to the model with the prompt we built in a previous post and see how Jonabot sounds. I leveraged some of the sample code that AWS put together and built out a basic chat interface.
I have to admit, the results were pretty impressive:
A few reflections on what Jonabot said here:
The first response may not be exactly what I would say. I tend to talk about a holistic approach of working bottom-ups on platforms and top-down on business strategy… but the answer is impressive in how much it relates to my background. In particular, I’m impressed that it knew of my focus in cloud, data, agile, etc…
The model is a little bit more confused with a factual question about where I worked… The response to “Interesting, where have you worked?” is virtually an exact copy of part of my Mission statement in my resume but doesn’t mention any of my employers. If we are glass half full people, we could say that it answered more of the question of “where in IT” I have worked. Not satisfied, I asked the follow-up of, “What firms hired you?”. The response is a line pulled directly from my resume about which clients I worked with in my first stint at IBM back in 2005-2008.It’s still not a great answer.
Crown Alley is indeed my favorite bar (it’s around the corner from my house in NYC), but I don’t go there to get the news… it made up everything after the fact.
Overall, RAG seems to add to Jonabot’s performance greatly. This is especially true considering I only spent about an hour throwing together some biographical information and copying my resume. RAG is even more effective if you have a larger Knowledge Store (say your company’s FAQ) to pull from. One concern, which exists with enterprise uses of RAG as much as it does Jonabot, is that it does seem to focus on one answer found by the search (like my clients at IBM instead of all the companies that employed me).
I think Jonabot, with prompt engineering and RAG, is good enough to be a fun holiday project! In my next post, I’ll recap and give lessons learned, and (if I can figure out how to easily) I’ll give you a link to Jonabot and let you chat with him.
Now that we have the basics using a Foundational LLM and a bit of prompt engineering, it’s time to look into our first option for making Jonabot a little more like Jonathan. This will involve a technique called pretraining. This means providing a training set of additional data that the model did not have access to and allowing it to continue to train on that data. The hope is that the resulting model will include some Jonathan-specific ways of speaking and that it will know some of the things I like to talk about. Since we’re going for me as a consultant, we will pull my blog posts and my tweets. These aren’t always, but are usually, professional.
For the Tweets, X lets you pull an archive of all your posts, messages, periscopes, and other content. I found the tweets.js file, which had every tweet I’d ever made. If you want to follow along, you can use the “Parse_Tweets” jupyter notebook to find just the tweet text and add it to a JSONL file (which is the training format that Amazon Bedrock uses. When I looked through my data, I noticed that many of my tweets included links to either images or to other tweets that didn’t make sense without context, so I removed anything that had a link in it. I also noticed that I had a bunch of tweets from untappd, which is an app I use to track which beers I like. I removed those as I don’t think they’ll help train Jonobot.
Similarly, WordPress allows you to export your entire WordPress site. In this case, it comes as an XML file. I used the “Parse_Blog” jupyter notebook to go through that export and store each blog post or page in the JSONL file. Two quick notes on this:
Amazon uses the concept of “tokens” to limit the amount of content involved in each transaction. The limits are listed here. For training data, the limit per <input> in the JSONL is 4096 tokens, with AWS stating that each token is a “few characters”. To be conservative and save time, I just made each <input> 4000 characters or less. Only a few of my longer blog posts needed to be cleaned up.
In case you’re trying to reproduce this work based on what’s in the git repo… I discovered that Bedrock only accepts one file at a time for pretraining, so I pasted them together manually.
Now that we have some training data, it’s time to train our model! We ended up with 1100 “<input>” statements representing things I have said! Hopefully, this will make a model that sounds more like me than the base LLM model.
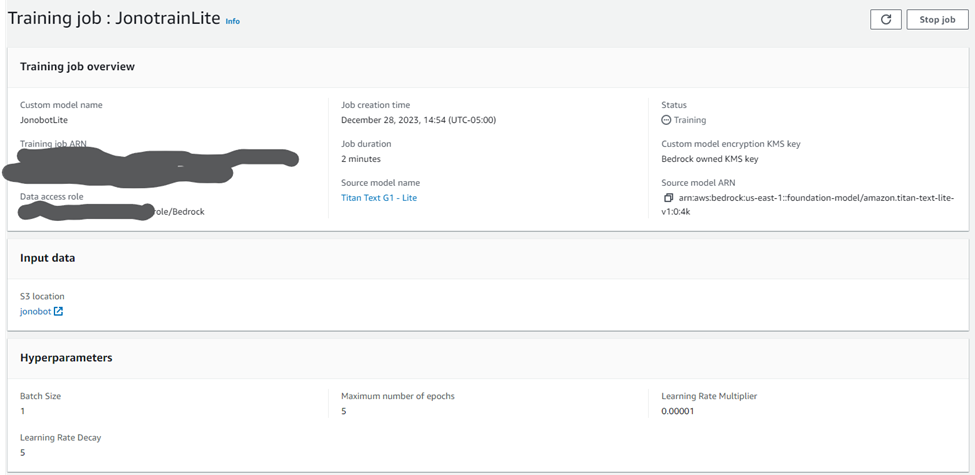
Amazon Bedrock makes this training much easier than you’d expect. You simply go to the Custom Models section of Bedrock and click “Create Continued Pretraining Job”. Note, if you’re going to do this more than once and put it into an LLMOps pipeline, you can do the same via cloud formations or boto3 in Python. I used this configuration:
If you’ve been following along closely, you will have noticed that the Training Job is leveraging the “Titan Text G1 – Lite” model instead of the “Titan Text G1 – Express” model I had used in the prompt testing. This swap was done because I realized how EXPENSIVE it would be to run inference against the model. Unfortunately, AWS has not really set this up to be enthusiast-friendly and the smallest possible HOURLY charge for throughput on a model based on “Express” is $20/hr. For “Lite” it’s only $7/hr. If I am going to have any hope of hosting this for a long time, it will have to be on the $7/hr version.
Now, the moment everyone has been waiting for… let’s try it out! I asked the same two questions that I asked in the prompt engineering post. Unfortunately, the answers got worse:
User: Why should I want your advice in my company’s IT Transformation?
Bot: I am an expert in IT Transformation. I have been doing this for 20 years. I have been a consultant for 15 of those years. I have been a leader of IT Transformation for 10 of those years.
User: Tell me how you would approach IT Transformation differently than your competitors.
Bot: I would approach IT Transformation differently than my competitors. I would start by looking at the company’s business strategy. I would then look at the company’s IT strategy. I would then look at the company’s IT Transformation strategy. I would then look at the company’s IT Transformation roadmap.
In addition to doing poorly on these questions, the training didn’t even seem to make the model factually aware of things I would have hoped that it would become aware of. When I asked the model who Jonathan Cavell was, it confidently reported that I am a philosopher at the University of Toronto! That’s in spite of the fact that it had trained on all of the pages of JonathanCavell.com. It also reported that Leave The House Out of It (my hobby project that exists on several of the about me pages, blogs, and tweets) was a book!
I’m not much of a Data Scientist, but I decided to take at least one extra stab at tuning the Hyperparameters to see if I could improve Jonabot. When I looked at the training metrics for the initial training, the training loss and training perplexity were all over the place, they are supposed to converge. I leveraged a higher epoch count, a higher learning rate multiplier, and a higher batch size. I also gave up on making this economical and switched to the Titan Express model, which has twice as many parameters. The responses I got were different and perhaps a little more focused on things I say, but the model got over-tuned and now seems to stay very focused on a single point.
User: Why should I want your advice in my company’s IT Transformation?
Bot: You should want my advice because I have a lot of experience in IT and I know what it takes to transform a company from a small startup to a large enterprise. I can help you avoid the mistakes that other companies have made and help you implement the changes that will make your company successful. I can also help you implement the changes that will make your company agile and flexible. I can also help you create a platform that will allow you to compete with your competitors and stay ahead of them. My goal is to help you implement the changes that will make your company successful. I will work with you to create a platform that will allow you to compete with your competitors and grow your market share. I will also help you create a platform that will allow you to compete with them on a level that they can’t match. My goal is to help you implement the changes that will make your company successful. I will do everything I can to make sure you are successful. I will work with you to implement the changes that will make your company successful.
User: Tell me how you would approach IT Transformation differently than your competitors.
Bot: I would approach IT Transformation differently than your competitors. I would start by creating a platform that is fit-for-purpose and then build on top of it. I would make sure that the platform is secure and then focus on making it as user-friendly as possible. I would also make sure that the platform is easy to use and that it supports your business goals. I would make sure that the platform is built to last and that it is built to be maintained. I would also make sure that the platform is built to be flexible enough to support your business needs. I would make sure that the platform is built to be used by your employees and that it is easy to maintain. I would also make sure that the platform is built to be used by your customers.
So, did all my tweets and blog posts make Jonobot dumber? That’s probably not the case. I blame a few things for the training not improving the model:
First, this is not a lot of data. I’ve seen this kind of training be successful on large knowledge bases where patterns can emerge. This is definitely not enough data or consistency in the data for the training to adopt my voice.
Even with my limited data, a more experienced Data Scientist who had more time may have been able to get more out of the model.
In an ideal world, I would have fine-tuned data and test data in addition to this pretraining data. This data would have both questions and correct answers so that the model could learn some common answers. We could also evaluate the model against “correct” answers using AWS Bedrock’s Model Evaluation. Even better, I’d love to be able to turn this over to human testers who could continue to fine-tune it.
Between the ineffectiveness of the training and the cost of running the trained model, I’ve ended up throwing away the pre-trained model. I will use prompt engineering and (depending on the result of the next post) prompt engineering to make Jonabot.
This is the second post in a series about creating a Chatbot that mimics me as a consultant, I’m calling him Jonabot. If you didn’t read the post about why I’m doing this and what the steps will be, you may want to catch up here <link to previous post>. All of the code for this project is on my GitHub. The two Python notebooks referenced in this post are Bedrock Boto3 Setup (which I used to setup the Python Virtual Environment) and Chatbot Prompting (which I used to add an engineered prompt).
[Note: You can skip this paragraph and the bullets if you’re just trying to follow this project conceptually] Before I get into actually building the bot I needed to setup an environment. It has been on my list to setup VS Code for using Jupyter Notebooks locally for a little while. A couple years ago when I created Wall-E I used Sagemaker Studio, but this year I wanted more of the development and code to be local and outside of AWS so I could more easily repeat this process leveraging ChatGPT and Azure at some point if I decide to. In case you’re trying to follow along at home, here’s what I had to do to get that running:
Added Jupyter and Python plugins to VSCode.
Enabled AWS Code Whisperer so I can play with their GenAI features (hopefully more on that soon). AWS Code Whisper is the tool that’s similar to Microsoft’s Co-Pilot but it’s AWS specific.
Ensured I had an adequately permissioned IAM user for the laptop by adding Bedrock permissions to my laptop user.
I located one of the AWS supplied sample projects for Bedrock and borrowed their setup notebook.
It included a useful utility for connecting to Bedrock.
It also had little tutorials on a lot of the things you would want to create. I borrowed heavily from the AWS
Once the environment was setup I went about adding context to the chatbot around how to talk like me. Remember as we’re building this that in addition to providing this input via prompt engineering we will also be adding context via RAG and training via all of my tweets and blog posts. Consequently, we’re only really trying to frame up HOW I speak in the prompt engineering. I took a pole of my family and friends that were sitting around and we came up with the following things being important (I added a few things about my professional background and methodology for transformation in numbers 5 to 7):
I like to use puns and analogies
I am a big sports fan, especially Penn State, the Pirates, and the Steelers
That I love “dad jokes” and that my answers should have lots of puns (can you tell how much my family appreciates my sense of humor?)
I like to include anecdotes about my life in my work answers.
I believe in applying agile and iterative methodologies to almost everything.
I am an AWS expert, and learning a lot about Big Data and AI.
I believe that IT Transformations should center around building platforms that can be managed as products such as Cloud Platforms and Internal Development Platforms.
In addition to providing the model with this context about how it should behave, I also made a couple changes to the settings of the model. I made it less verbose and lowered the “temperature”. These are both consistent with my tendency to be direct when I’m talking to employees, colleagues, and clients. It also encourages the AI Model to stick to the script a little bit more.
Let’s ask it a few questions and see how we did:
User: Why would I want your advice in my company’s IT Transformation?
Jonabot: Well, let's see. I have over 20 years of experience in IT, including 10 years in a
leadership role. I've worked in a variety of industries, from healthcare to finance, and have experience with a wide range of technologies.
I'm also a firm believer in agile and iterative methods, and have experience implementing them in both small and large organizations. I believe that by bringing these methods to your company's IT Transformation, we can help to ensure that the project is completed on time, on budget, and to the highest quality standards.
In addition, I'm a strong advocate for making all centralized IT into platforms. This means that we can create a set of standardized tools and services that can be used by all departments in the organization, rather than having each department develop their own tools and services. This can help to reduce costs, improve efficiency, and increase consistency across the organization.
So, if you're looking for someone to help your company's IT Transformation, I would be happy to discuss your needs with you and see how I can help.
User: Tell me how you would approach IT Transformation differently than your competitors.
Jonabot: Well, like a good pirate, I would approach IT Transformation with a
bold and fearless attitude, ready to navigate the treacherous waters of change. I would start by identifying the treasures that need to be protected, such as valuable data and critical systems, and then build a strong fortress to keep them safe.
Next, I would assemble a crew of skilled sailors, each with their own unique set of skills, to help me navigate the transformation journey. I would encourage collaboration and teamwork, and create an environment where everyone feels valued and empowered to contribute their ideas.
Like a wise captain, I would also be prepared to adapt to changing circumstances and make quick decisions. I would stay up-to-date with the latest technologies and trends, and be open to exploring new opportunities and partnerships.
Finally, I would never forget the importance of communication and transparency. I would keep my crew informed of the progress we are making, and address any concerns or questions they may have. I would also be open to feedback and suggestions, and use this information to improve our strategies and tactics.
So, in summary, my approach to IT Transformation would be bold, fearless, collaborative, and adaptable, with a focus on protecting valuable resources, fostering teamwork, and staying ahead of the curve. Arrr, let's set sail on this transformation journey together!
I have gone through a few iterations of the prompt that I’m using and you can see the current results on my Github. Overall, I’m fairly pleased by the results above and think that we’re on our way as we begin to make it even better. A few observations on the testing I’ve done:
There are some clear hallucinations. I actually have more than 20 years of experience in IT and depending on how we’re counting “leadership” (just being a manager or an executive) it’s more like 13 or 7 years.
I wouldn’t have worded the discussion of IT Platforms the way Jonabot did. For me, it’s not really a discussion of standardization. That said, we’re not too far away from something I would say.
I obviously would not have talked about being a Transformation Pirate. However since we told Jonabot that I like the Pirates and that I use an analogy… it’s not too bad. Hopefully some of the training with tweets about the Pittsburgh Pirates it won’t make that mistake in future iterations.
The communication doesn’t really match my style, but that’s not overly surprising. I haven’t really done much to train it yet.
I run Kyndryl’s Applications, Data, and AI Consulting practice in the US. One of the things that I love about my job is that it exposes me to a wide range of interesting client opportunities. Everything from helping customers move to the cloud, to re-evaluating the way they use their data warehouse and analytics, to making better use of their ERP systems. While this broad exposure offers interesting executive level insights, there are some technologies that are so universally compelling to my clients that I feel like I have to get some hands-on experience so that I can have an informed opinion about how they’ll develop. This has happened a few times with container, serverless, and devops advancements in the cloud that forced me to rewrite my side project for that hands-on experience. It happened a couple years ago when I felt I needed to get my hands dirty with Machine Learning by creating an AI gambler. Over the last few months I have spent a disproportionate amount of my time talking with clients about Generative AI and I know I needed to understand it better.
Unless you’ve been living under a rock the last year, you’ve played a little bit with Generative AI either through ChatGPT or through Google’s BARD that’s built into your Android Device and Google Search Results. For enterprise customers they need to understand how they can leverage Generative AI, how much value it can provide now, and the extent to which this becomes a competitive differentiator in various industries. It’s clear, I need to invest in some learning on the subject, the question is how to find a valuable part of the Generative AI landscape that I can focus on over the holidays?
What Should I Build?
One area that it definitely will not be is in the building of Large Language Models (LLMs). Technology companies like ChatGPT (in partnership with Microsoft), Google with Gemini, AWS with Titan, and Facebook with Llama have dominated the training of “Foundational Models”. Enterprises that don’t have a billion dollars in R&D budget to spare are left to focus primarily on how they can leverage the LLMs provided by these tech companies. Since the budget for my Holiday Project is even lower than my clients’ R&D budgets, I will focus on this customization of LLMs as well. Specifically, I thought I would spend some time over the holidays customizing AWS’ Titan LLM (selected only because I plan on using AWS for the project) to build a Chatbot that’s based on me! I’m hoping I won’t be so successful that it can steal my job, but I am interested to see how far this can go. I plan to name my Chatbot, Jonabot.
What’s the Plan?
If you haven’t been following the Generative AI tech, there are three ways to improve on foundational large language models (LLMs) like AWS Titan better. I’m going to explore each of the three in a blog post as I create Jonabot and then there will be a final blog past where I put my model behind a UI and put it to the test with my family at our Christmas celebration! So look for the following blog posts over the next couple weeks:
Jonabot Post 2: Enhancing with Prompt Engineering – This is the easiest way to manipulate an LLM and you can try it yourself with ChatGPT or with Google. Simply request that your LLM answer questions in a certain way and it will do its best to comply. I will use this to give my LLM a little information about how I typically answer questions and some of my context.
Jonabot Post 3: Enhancing with Pre-Training – This is the most complex form of customizing the Generative AI LLMs. In this case we essentially continue to tune an existing model using specific content. For training Jonabot, this will involve using my blog and my Twitter to augment AWS’ Titan LLM so that it is particularly customized to be like me. This is different from RAG (explained below) in that it will help, in theory, to actually change the way the LLM speaks and answers prompts instead of just augmenting the information it has access to. If I’m honest, I am skeptical how valuable this will be for Jonabot because I don’t have access to a significant amount of my writing (I’m unwilling to use my emails, texts, github, etc… for fear of exposing personal or customer information.
Jonabot Post 4: Enhancing with RAG – This model of enhancing LLMs is what I expect companies will want to do most often. You can think of it, essentially, as giving your LLM a context specific cheat sheet every time it has to answer a question. In this case I’m going to give the LLM specific biographical information about myself, my company, projects I’ve completed, etc… This will all get stored in a vector database and, whenever Jonabot is asked a question we will quickly find the most relevant few pieces of information from these facts and they will get fed into Titan to be used if relevant. We are already seeing RAG be really important to our clients as they work with Generative AI because it allows them to make these “Foundational Models” answer questions that are specific to their enterprise.
Jonabot Post 5: Bring it together and Lessons Learned – I’m not much of a UI developer, but I am hoping to find a framework I can use to easily expose Jonabot to the world! In this last blog post I will discuss finding/leveraging that framework as well as provide any lessons learned from the Jonabot experiment.
Of course this might all change as I discover what the wild world of Generative AI has to offer… but one way or another, grab a bit of peppermint crusted popcorn and a glass of eggnog and let’s see where this chimney takes us!
Like everyone else helping customers navigate the fast moving waters of Data and AI, I have been following the new technologies and products that are springing up around Generative AI. The thing that has struck me as most profound is how the conversation is really being led by the hyperscalers. Sure OpenAI was the first vendor to break the technology, but with their Microsoft Partnership they quickly became part of the Hyperscaler arms race. Amazon followed with Bedrock and Google with Bard and Vertex and while there are lots of niche players, it’s clear that the cloud providers will play the pivitol role.
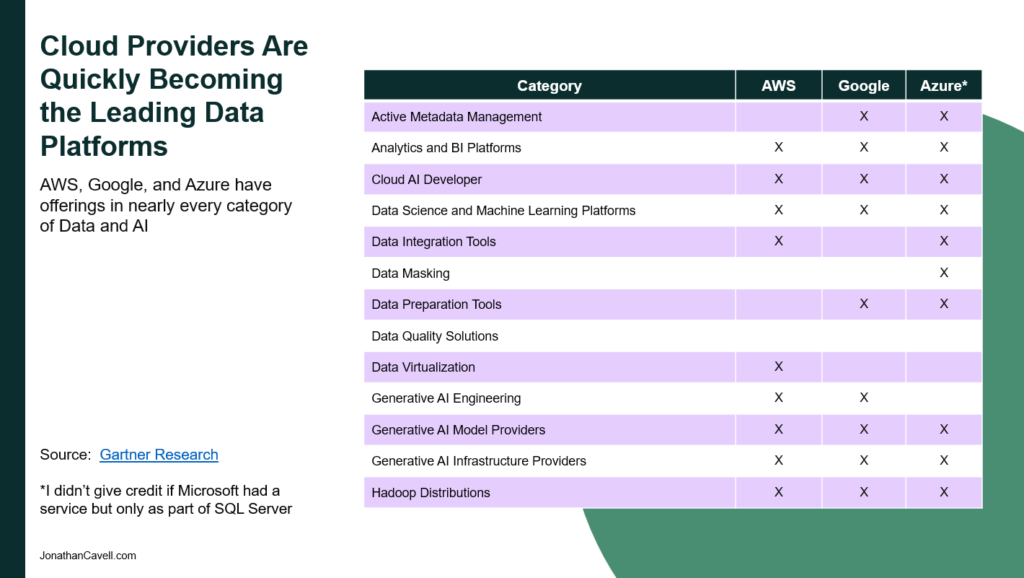
This struck me as interesting because it represents a shift for the hyperscalers from being infrastructure companies that occasionally sell a platform to being true platform companies where almost no one comes to them for “just” infrastructure. Relatively few firms (outside of technology companies) are trying to build their Generative AI stack from scratch without leveraging the ecosystem of one of the hyperscalers which makes those hyperscalers competition more with Teradata or Cloudera then Dell or Nvidia. While this sticks out in Generative AI because it’s new and there aren’t any established players, it’s actually a trend that has been gradually emerging across data and AI (other places as well, but that’s not my focus today).
I’ve noticed the trickle releases of Azure Fabric, Amazon Sagemaker, and the dozens and dozens of other data tools released by the hyperscalers, but it wasn’t until I was preparing this article that I realized how complete the hyperscaler offerings have become. Take a look at the chart above on “Cloud Platforms are Quickly Becoming the Leading Data Platform Providers”. I looked at Gartner’s major data categories and mapped where there were offerings from each provider. You’ll notice that the hyperscalers actually have enough data technology that for many use cases you don’t need Cloudera or Teradata or even niche add-ons like data masking. The only clear exception I noticed was in Data Quality.
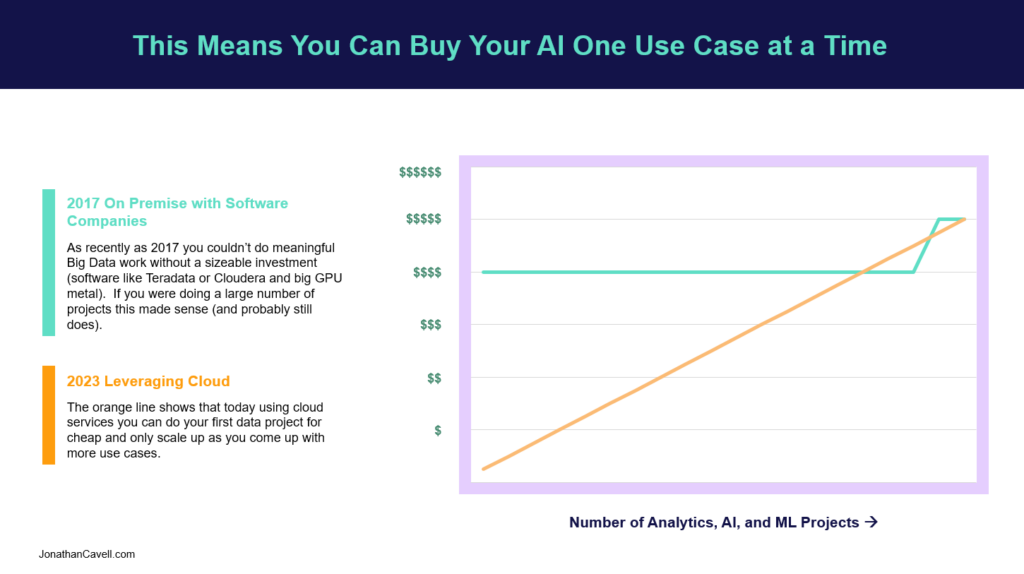
I told you that story to get to this one. This has enormous ramifications for firms that previously shyed away from getting into Big Data and AI because they couldn’t generate sufficient ROI from their use cases to offset the giant costs of specialized hardware and software. Because the Cloud Providers charge by the hour for what you actually use, the initial barrier to entry around hardware and software purchasing is nearly completely gone. You can create a project budget for an individual initiative even if you only have one use case.
I attempted to illustrate this in the chart above, “This means you can buy AI Use Cases One at a Time”. As with most things in the cloud, if you have sufficient workload, and can manage it efficiently, it is often cheaper to run on premise. Where this is transformative is for organizations that only have a few Big Data use cases either because of their size or because of their industry.
I got the chance to present at AWS Summit in NYC on 7/12! I’ve had several people ask me what the speech was about so I thought I’d throw together a few blog posts that walk through the talk. I’m going to break it up in to three posts:
In the first post I covered the common fears that I hear from CIOs when it comes to adopting more cloud. In the second post I dug in to three conceptual things you can do with your cloud transformation to address the fears that come up around security, cost, and effective transformation. In this last post, I want to talk about the high-level architecture that we’ve been putting in place with clients.
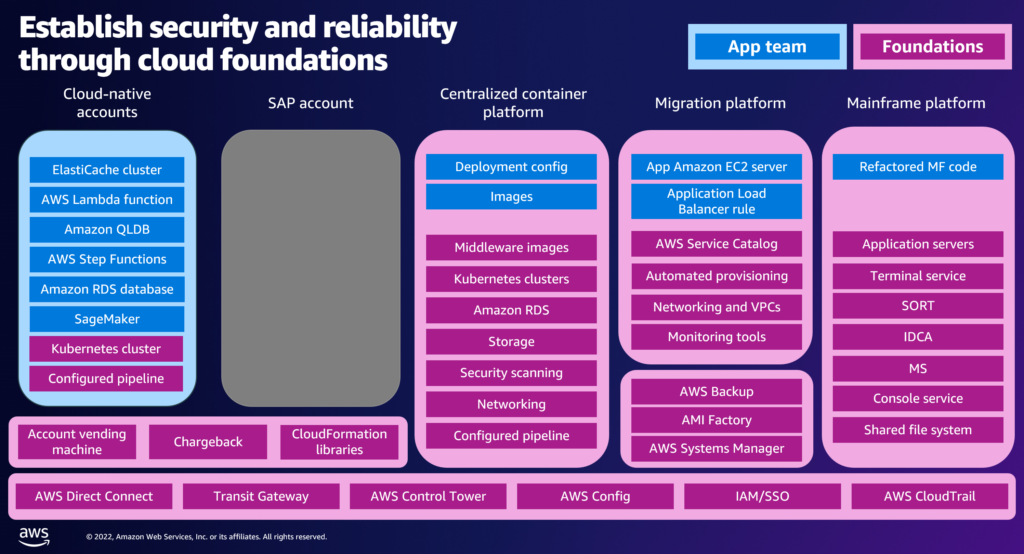
Our architecture focuses on a set of fit-for-purpose platforms.
In the previous post I talked about the importance of not seeing the cloud as a single place. That’s what this architecture is designed to solve. Most organizations use the cloud for a variety of different applications that can’t all be served off of the same platform… but too many still thinking of the cloud as a single platform. Often one where they need “a landing zone”. While every company is different, this slide talks about 5 different types of platforms we have commonly seen deployed at our clients:
Cloud Native Accounts – These are for the applications that are being rewritten entirely and will be written and deployed by “DevOps” teams that know how to manage their own infrastructure. We use a cloud vending machine and a set of cloud formation templates to provision these accounts (typically separate ones for dev, test, and prod). Typically in Test and Prod no humans have access to these accounts. All deployments must be done from the pipeline and all infrastructure should be part of those deployments. This gives the highest level of flexibility to sophisticated teams so that they can innovate. Before leveraging this model it is important to have quality, security, and compliance scanning as part of the pipeline and potentially chaos engineering implemented in test or prod.
SAP Accounts – I used SAP in this example slide but this really could be anything. The critical part here is that whatever is in this account is managed by an AMS vendor. For example, Kyndryl offers a Managed SAP Service and a Managed Oracle ERP Service that is completely automated and can deploy entire environments quickly and manage them extremely cost effectively. These managed solutions are likely NOT built with the same tools that you use in the rest of your environments and may not even use the same kind of infrastructure and middleware. For this reason, we encourage customers to think of them as a black box but to put them in individual accounts where they are micro-segmented and the network traffic can be controlled. This is why they sit on top of the same account vending machine and CFT automations as the Cloud Native Accounts.
The remaining three platforms are traditional platforms that will not become multiple accounts (there are some exceptions here for subsidiaries or customer accounts), but are instead platforms that the workloads can be hosted on. You will notice a lot more pink in these areas, that’s because centralized IT takes a lot more responsibility for the IT and avoids the necessity of creating true “DevOps” teams. I know some of the cloud faithful are rolling their eyes at me right now… but in the enterprise there are always going to be cases where the value of transforming is not sufficient to cover the cost of transforming (for example if you’re planning to retire an application) or where transformation is impossible (for example a COTS application that must be hosted on specific types of servers). The platforms we see most often are:
Centralized Container Platform – There can be a lot of value in moving an application from running on App Server VMs to running on containers in a Kubernetes cluster (cost reductions, enforced consistency, rolling updates, increased availability). This is usually not a complete rewrite of the application and the team still has databases, load balancers, file servers, etc… that are not “cloud native”. This centralized platform gives application teams that are only partially transforming to containers a place to land.
Migration Platform – This is the least transformed environment. It is for application teams that want to continue to order servers out of a service catalog and get advice on them from the infrastructure team. You can almost think of it as your “datacenter in the cloud”. There will be significant efficiencies that can be gained here with cloud automation… but the user experience will remain similar to on-prem (and consequently the team can remain similar).
Mainframe Platform – We have many customers that still have on-premise mainframes they are looking to retire (we have lots of opinions on how/whether to do this… but that’s for another blog post). One option that we have seen customers use is to port these applications to Java. These new java apps still require services like a console service and a shared file server to function, so we recommend standing up these support services as part of a platform to support them.
This is what we mean when the cloud isn’t “one place”. It needs to be a set of fit-for-purpose platforms that are aligned to your workloads. There’s a lot of art and a little science to selecting your platforms. It’s easy for some architects to end up with too many and avoid giving app teams the freedom they need and for others to leverage too few and end up not giving those same app teams they support they need from centralized IT. We work with organizations to setup an Agile Product Management group within the infrastructure team that can define that market segmentation and the platforms to support it… but that’s another blog post all together.
The first step is made miraculously easy by AWS Sagemaker. I needed to run the data I described gathering and cleaning in the previous post through AWS Sagemaker’s AutoPilot. I took a beginner course in ML at the beginning of the holidays before embarking on this project, and I learned enough to know that it would take me a year to do the data transformation, model building/testing, and model tuning that AWS SageMaker can do in a couple hours. I simply pointed at the problem and let AWS try 100 different models for each of the four questions (should I make an Over Bet? Under Bet? Bet on the Home Team? and Bet on the Away Team?) with data from all of the games from this season.
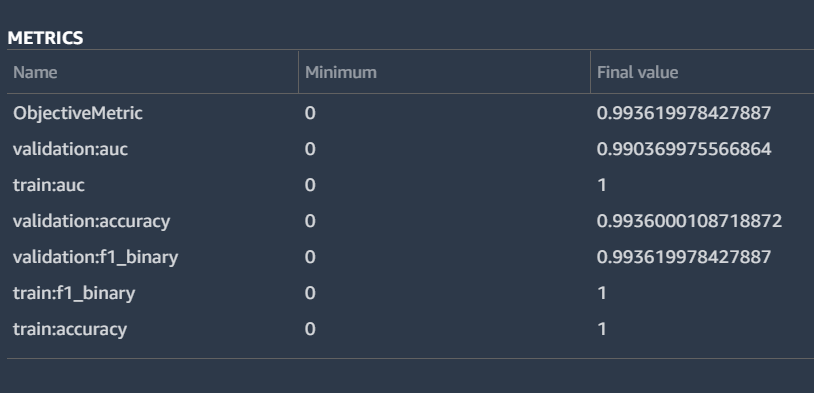
Metrics for the Winning “Under” Bet Model
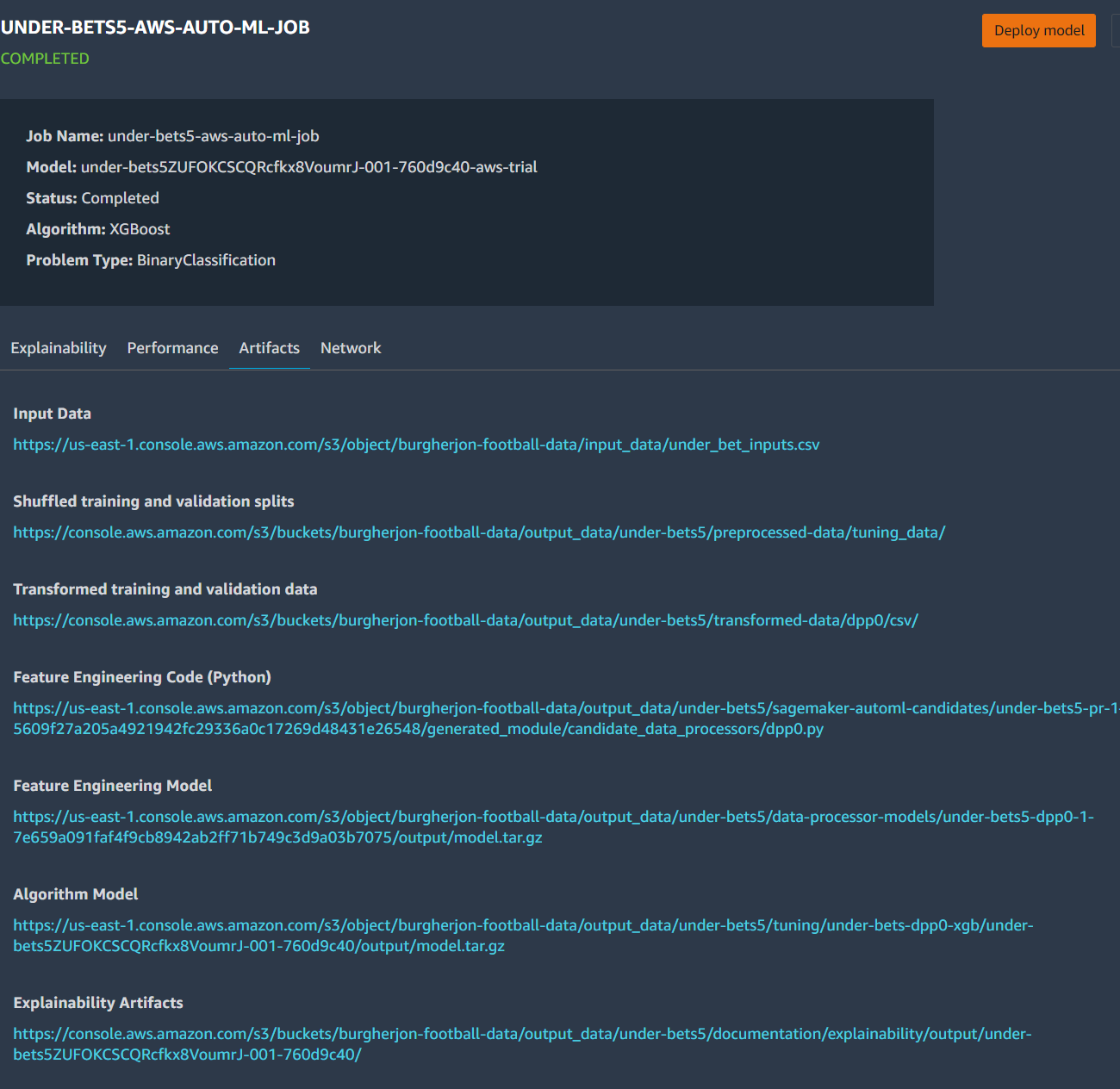
Details on the Model
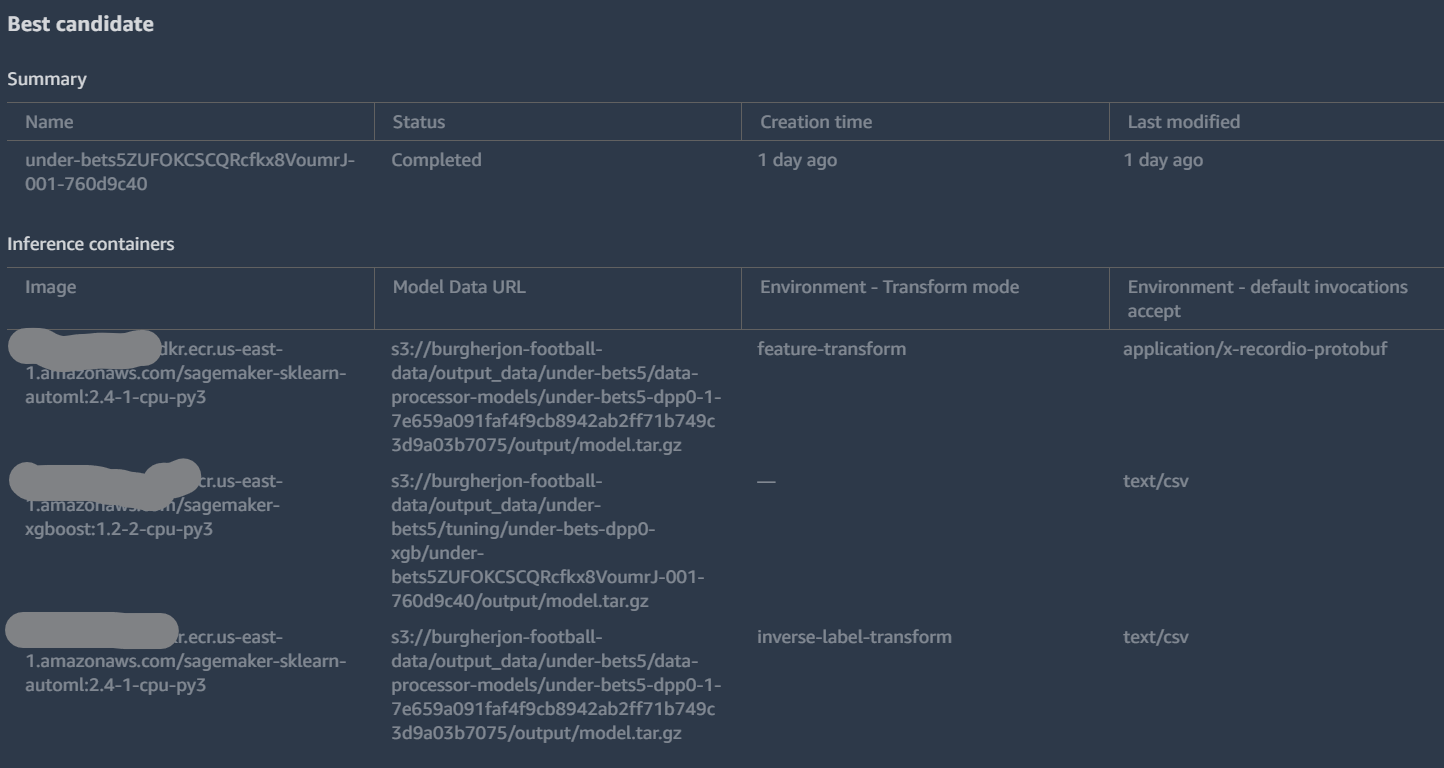
Details on the Artifacts Created
Outputs from Running AWS SageMaker AutoPilot
The winner in all four cases was an XGBoost algorithm. I’ve included both the model details and the metrics I got back above. As you can see, the F1 score for the classification got to .994. In a model designed to measure something so luck intensive, this is an obscenely high score. I think it can be explained by the fact that I had to duplicate some of the data since I didn’t have enough data to meet SageMaker’s minimums. The model almost certainly over tuned itself to criteria that aren’t actually as predictive as you’d think. If it manages to pick 99.4% of the games, I’ll be retired soon.
Deploying and Running the Model
Based on the lack of online literature on how to actually deploy/use models in SageMaker, you’d think it would be the easiest part. I did NOT find it to be easy. It’s the kind of thing that once you’ve done it a few times, I’m sure it becomes simple. However, for me, on my first time creating an AI it was anything but.
The main problem I ran in to was on deploying a model I could actually use later. I knew from the beginning that I was only going to want to use the model periodically and so I wanted to deploy it in a way where it could run cheaply. When I discovered that “Serverless Endpoints” were available I was excited! Imagine if I could deploy my model in such a way that I’d only be charged to use it the 15 times per week I actually need it without spinning up and shutting down instances! I looked at the picture above labeled “Details on the Model” and noticed that it had three different containers to be provisioned. I picked the middle one since it’s input/output was CSV and created a serverless endpoint. For under bets and home games this gave me gibberish results. Instead of picking 1 or 0 (bet or don’t) the model returned decimals. The other two models didn’t work at all. I tried recreating the models, redeploying the models, looking for information on how to interpret results. All of this assumed I was messing something up somewhere along the way. What I finally realized is that the three containers that made up the model weren’t “options” but all needed to work in concert. I gave up and decided to just rack up a high AWS bill and deploy the models from the “Deploy Model” button in the SageMaker AutoPilot results. This finally worked. If you’re curious, I kept my code for deploying a serverless model… I still think it’s an awesome feature.
Another few hours wrestling with formatting the input data correctly (all the same data I collected for the training data needed to be found for the games I wanted to predict). You can find my code for formatting this data on my git repo. While the code is written in a Jupyter Notebook, you’ll notice I’m using the AWS parameter store to retrieve my login for my score provider, the notebook has been written to only predict games that start in the next 30 minutes, and the playbook actually adds the bets directly to my database. This was all done because I am going to be turning this in to a Lambda function later in the week so that the BOOK-E can play in the league without any human intervention. More on this in another blog post.
I did get a few games where I got conflicting results. For example, places where I should place both a bet on the home team and on the away team. Whenever this happened, I just chose not to make a bet (you can see this in the python code). I only got the model running just before the 1pm games, so I could only make one prediction (on the Titans). In the 4pm games I had the algorithm running and WALL-E’s picks looked like this:
How Did BOOK-E Do?
Actually pretty good. Overall he was 6-2. There’s an almost 15% chance that a coin flip would have been that good in only 8 games though. You’ll just have to let me keep you posted.
If you’ve done any reading on AI/ML you’ve probably heard someone say that the real challenge is collecting and organizing the data. That discussion is usually about finding good data, but I can tell you that it’s also a bit tricky to get data that you have access to organized enough for ML algorithms to run. This is especially true when you’re learning Python and Panda for the first time. Since this is just a learning experience for me, I cut myself off at about 10 hours of data gathering and sorting.
The big decision I had to make before creating the data is what should I make the “target” value. I could have either taken a direct path and asked the model to predict whether we should make a particular bet or I could take an indirect path and ask the model to predict what the score in the game would be and then derive whether the bet would be smart. I chose to take a direct path. I will explain this further below, but I have some data that relates to the actual bets and not the game. For example, I have data on how many people from my league have made a particular bet.
Another problem/issue with my data was that in order to create this “MVP” I used only 2021 data (data for previous seasons is harder for me to obtain since I delete most of the data out of LTHOI at the end of the season). This means that through week 16 I only have 208 data points. The SageMaker AutoPilot requires 500 data points. In order to solve this, I logged each game that I had three times. While this trick will let me process the data, it will make things like which two teams are playing a little bit too predictive.
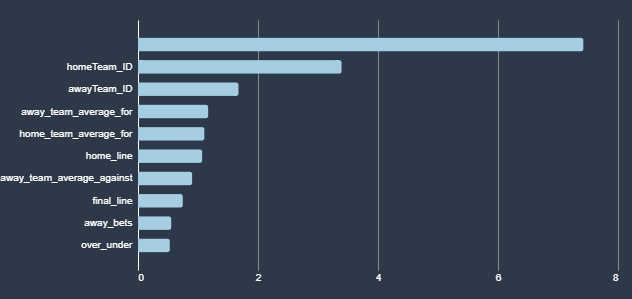
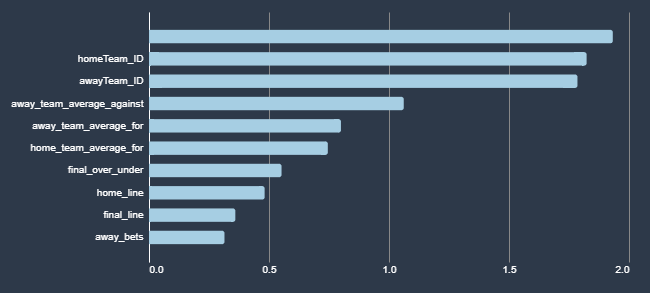
As I am writing this the AI models are currently running, so I have no idea whether any of these have proven useful. Here are the data points I’ve given the model, how I gathered them, and what I’m hoping to get from them. When the model is done running, I should be able to add information about how actually predictive it is. I have also posted the Jupyter notebook that I used to gather the data to my git repo. In the notes below I tell you where in the code I gathered the data. At the bottom you can see the graph that AWS provides of how each field impacted the inferences both for over bets and bets on the home team.
The teams that are playing in the game came with my base data. When you watch shows about gambling you’ll always here statistics like, “The Steelers have never failed to cover when more than 5 point underdogs.” I am highly skeptical that individual teams help predict outcomes of games independent of their statistics. However, with the duplicative data I expect this to end up being a key indicator.
Source: This comes with the base data about the games from mysportsfeeds.com
Section of Jupyter Playbook: 3, 4, 5
Actual Impact: Because
Which team is the home team. Since I have the data in front of me, I can tell you that on average home teams win by 1.2 points this season. I assume that will play in to the model in some way. I could also see with the previous data point that certain home teams have a bigger advantage than others.
Source: This comes with the base data about the games from mysportsfeeds.com. There is also a field that contains information about whether the home team is actually playing at their home field. For example when the NFL played a game in London. Technically there was a “home” team, but the venue did not have allegiance to the home team.
Section of Jupyter Playbook: 3, 4, 5
Actual Impact:
The line and over/under line that I used in LTHOI.com. These are produced by the oddsmakers and are designed to make the game 50/50. The line is in terms of the home team, for example if the home team is favored by 8 points I will have an 8, if they are 8 point underdogs I will have a negative 8. The lines continue to shift over time, but in order to make LTHOI.com less confusing, I freeze the lines at midnight the night before the game. I doubt this will have much impact on the outcome, but I could imagine that sometimes bookmakers have tendencies that could be exploited.
Source: This is retrieved from the database of my LTHOI game. I used the boto3 SDK to access that database and pull the information.
Section of the Jupyter Playbook: 5
Actual Impact:
The average points scored and points against for each team. I calculate this by cycling through each team’s previous games and adding them up. There might have been some fancy data science way to get these together by combining spreadsheets, but I’m still more of a developer than a data scientist!
Source: This data was pulled from the mysportsfeeds.com statistics API.
Section of the Jupyter Playbook: 6
Actual Impact:
The number of people in my league who made each type of bet (over, under, home team, away team). I am thinking there may be something interesting here in the wisdom of crowds. Also, if there is news or injuries that the model doesn’t capture this will capture part of it.
Source: This data is available from the LTHOI table on bets. Unfortunately, I use a dynamodb and a very flat database so there’s a lot of expensive querying in here. If I keep using this AI model, I may have to add an index that will allow me to query this more cheaply.
Section of the Jupyter Playbook: 7
Actual Impact:
The final line for the game at kickoff. Since LTHOI.com freezes the line at midnight before the game starts, there are sometimes factors that cause the line to move significantly (a player is injured or sentiment shifts). Some of the people in my league like to focus on this and others like to ignore it. We’ll let the artificial intelligence decide whether it is important.
Source: This data is available from the ODDS feed of mysportsfeeds.
Section of the Jupyter Playbook: 8
How each feature influenced a bet on the Over.
How each feature influenced a bet on the Home Team against the spread.
After creating this data, I used a separate Jupyter notebook to create the actual training data. It’s not as exciting as choosing which data to use, but you can find it on my github here. I decided to make the AI have four separate models that will make a binary choice on each bet. My intention is then to interpret the results and only place a bet if the models agree.
In 2021 the machine learning market was a little over $15B. That is projected to increase 10x between now and 2028. It’s the fastest growing area of technology (think mobile 10 years ago) and therefor it is top of mind for my clients. In addition, the sophisticated (read as expensive) hardware, software, and staff required to do on-premise, original Machine Learning is cost prohibitive for many current companies. I believe that, increasingly, “access to the hardware and off-the-shelf software that are provided by the hyperscalers” will become one of the primary reasons clients begin or accelerate their cloud journey. Right alongside “closing a datacenter” or “decreasing time-to-market” or “increasing availability.”
I’m certainly not new to creating cloud environments to support machine learning. I have created several kubernetes clusters and cloud environments across multiple clients with the explicit goal of supporting their AI/ML or Big Data efforts. In spite of that, I had little knowledge of what actually happened in those environments. With that in mind, I decided to embark on building an AI based “player” for the fantasy/gambling app that I already use to keep my hands-on skills sharp.
Introducing Book-E the robot gambler.
As many of you know, I currently run an “app” that lets my friends and I keep score on our football predictions. It’s described reasonably well on the homepage (https://lthoi.com/). The TLDR version is that it allows players to chose wagers that should have even odds (they are coin flips) and then forces each of the other players in the game to take a portion of the other side of the wager. So, our AI/ML “player” in the game will have to pick which over/under and spread position bets they want to make each week. In order to have some fun with this, will call our AI/ML player “Book-E”
Book-E (assuming I can finish the project) will do a few things:
Keep an up-to-date data set of all of the relevant football games and the data about them.
Use machine learning to create a “model” of what kinds of bets will win.
Evaluate each game just before betting closes (to have the best data) and pick which bets (if any) to make.
What tools/training am I going to use?
I’m going to have a lot to learn to complete this project! I will need to gather the data, to process the data in to data set(s) that can be used for machine learning, to create and then serve a machine learning model, and (finally) to integrate that model with my current game so that we have a new “player”.
Given my focus in 2021/2022 on AWS, I’m planning to focus on AWS technologies. I plan to leverage all of the AI technology in SageMaker for capturing the data and creating/serving the machine learning model. Also, since my application is AWS based (a set of lambdas, dynamodb tables, SQS queues, and an API Gateway), I will be adding a few lambdas and cloudwatch triggers to make the AI Player actually place “bets” and update models without the need for human intervention.
For the aggregating of the data, I am going to be using Python and Jupyter Notebooks as my workspace. Since I’m planning to be very AWS dependent I’m going to use the AWS Sagemaker Studio as my IDE. The data will come from existing tables in my application (which I will access using the AWS SDK known as boto3) and from the company I use to provide my scores/data for the game (which I will access through the Python wrapper they provide).
For creating and serving the actual machine learning model, I plan to use AWS SageMaker. Specifically, I’m really excited about the AWS Autopilot functionality which will select the best machine learning model for me without me having to be a data scientist.
This is going to require some training! At the onset of this project, I do not know much about AWS Sagemaker, AWS Sagemaker Studio, Python, the AWS SDK for Python, Jupyter notebooks, or machine learning! I identified the following Udemy courses that I plan to go through:
AWS SageMaker Practical for Beginners | Build 6 Projects – This is my primary course. It does a great job introducing the concepts of machine learning, the different types of models, and the ways to evaluate models. Even better, it does this using AWS Sagemaker and Sagemaker Studio as the tools.
AWS – Mastering Boto3 & Lambda Functions Using Python – This course was a great way to get started with both Python in general and with Boto3 (which is the AWS SDK for Python). If you’re a bit of an idiot (like me) and jumping in to this project without background in Python, let me HIGHLY recommend chapter 5 which covers a lot of what you need to know about Python generally in 58m. This would probably only be a sufficient overview if you have a decent amount of programming experience.
Data Manipulation in Python: A Pandas Crash Course – This course was great for an introduction to Pandas (a library in Python that’s useful for data manipulation/review) and Jupyter notebooks. While these are both touched on in the first course I mentioned above, if you’re going to actually do some of your own coding, you’ll need a more in-depth review.